根據超連結的完整文字內容來定位元素。
簡單來說就是有連結的文字,
這是參考文章的示範,⬇️⬇️⬇️ 「 關於 Google 」
我們拿旁邊的 「 Google 商店」來學習一次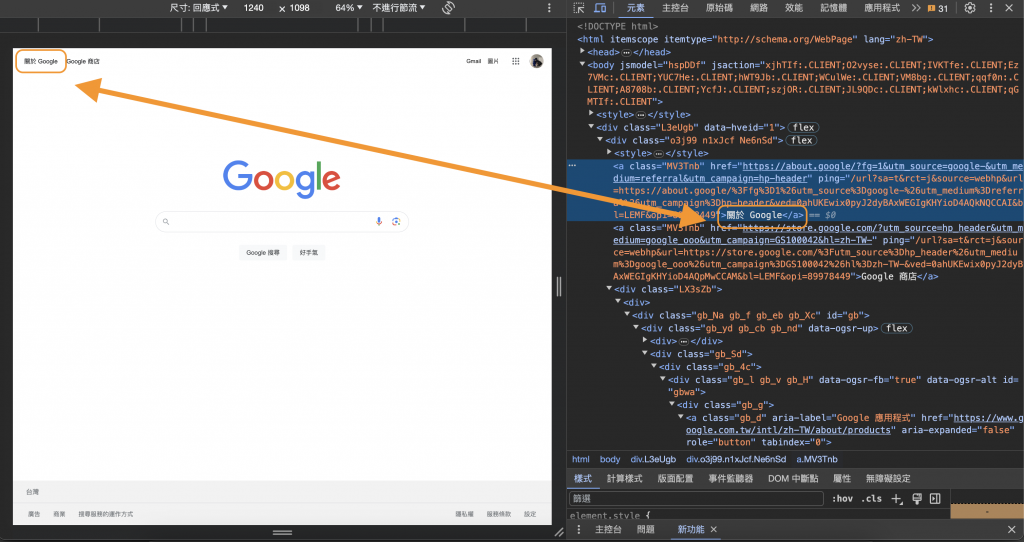

from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.google.com/")
element_by_link_text = driver.find_element(By.LINK_TEXT, "關於 Google")
print("LINK_TEXT:", element_by_link_text.text)
driver.quit()
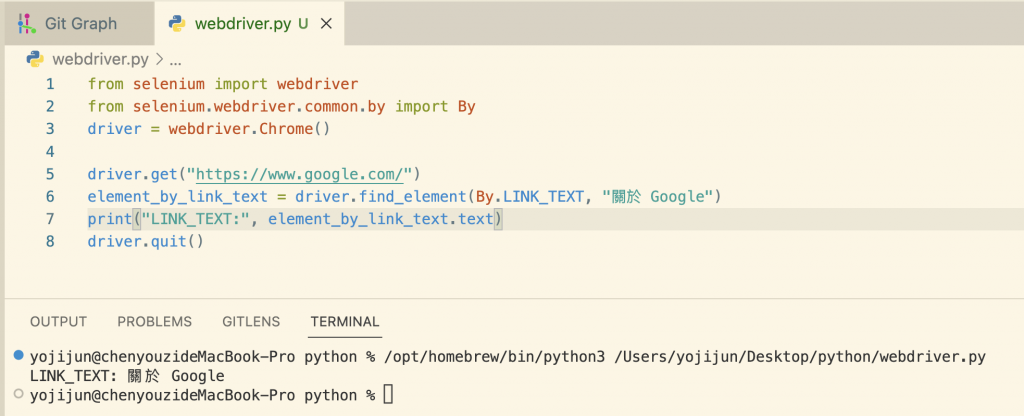
看起來有成功找到要的元素!
根據連結文字的部分匹配來定位元素。
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.google.com/")
elements_by_partial_link_text = driver.find_elements(By.PARTIAL_LINK_TEXT, "Google")
for element in elements_by_partial_link_text:
print("PARTIAL_LINK_TEXT:", element.text)
driver.quit()
結果輸出是
PARTIAL_LINK_TEXT: 關於 Google
PARTIAL_LINK_TEXT: Google 商店
從 driver.find_element() 改寫成複數 driver.find_elements() ,
並跑迴圈,列出符合條件的。
如果頁面上有多個元素具有相同或部分相同的連結文字,沒寫成複數並跑迴圈,他只會返回第一個匹配的元素。
partial 本意就是 局部的。
總之,
LINK_TEXT 完全匹配連結文字,只有當整個連結文字與指定的文字完全相符時,它才會找到元素。PARTIAL_LINK_TEXT 不需要完全匹配連結文字,只需要連結文字的一部分能夠匹配成功即可。獲取網頁上具有特定HTML標籤的元素,例如: 連結元素或所有的 表單元素。
也可以處理多個相似的唷
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://example.com")
# 使用 TAG_NAME 找到所有的 <a> 元素
elements_by_tag_name = driver.find_elements(By.TAG_NAME, "a")
# 遍歷所有的 <a> 元素並打印它們的文本內容
for element in elements_by_tag_name:
print("Link Text:", element.text)
driver.quit()
夜深了 最後兩個 我看了頭好痛 OAO
先附上簡約的 code
感覺半年內我用不到 明天還要上課 快逃
element_by_xpath = driver.find_element(By.XPATH, "//h1[@class='header']")
print("XPATH:", element_by_xpath.text)
element_by_css = driver.find_element(By.CSS_SELECTOR, "h1.header")
print("CSS_SELECTOR:", element_by_css.text)
動態網頁爬蟲第二道鎖 — Selenium教學:如何使用find_element(s)取得任何網頁上能看到的內容(附Python 程式碼)


 iThome鐵人賽
iThome鐵人賽